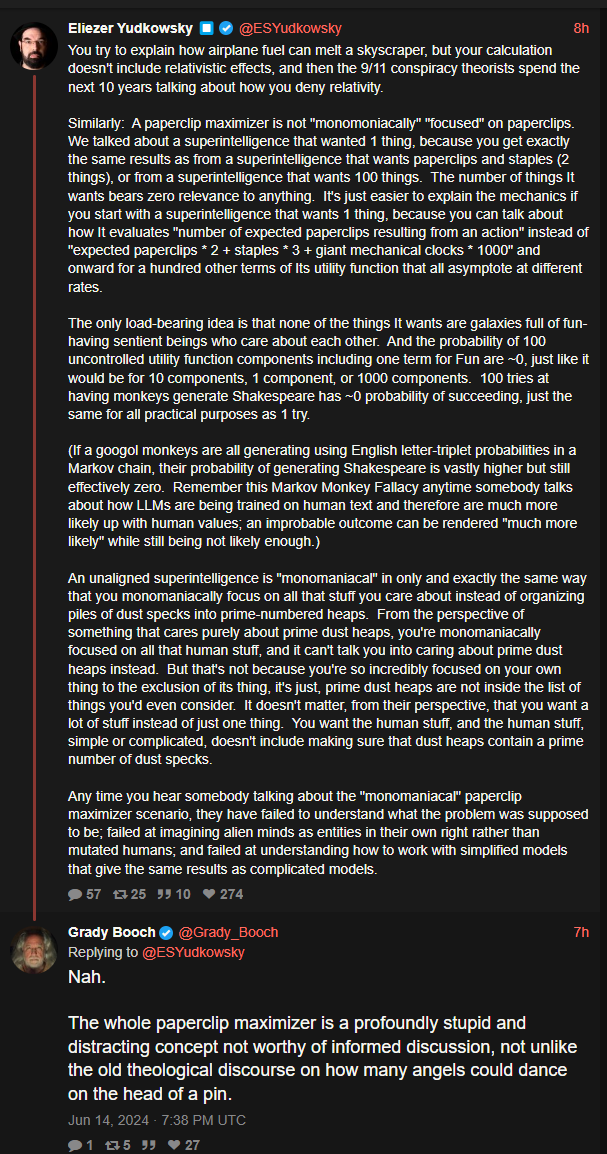
Before we accidentally make an AI capable of posing existential risk to human being safety, perhaps we should find out how to build effective safety measures first.
You make his position sound way more measured and responsible than it is.
His ‘effective safety measures’ are something like A) solve ethics B) hardcode the result into every AI, I.e. garbage philosophy meets garbage sci-fi.
yeah it’s been absolutely hilarious to watch this play out in LLM space. so many prompt configurations and model deployments with so very many string-based rule inputs, meant to be configuring inviolable behaviour, that still get egregiously broken
and afaict none of the dipshits have really seemed to internalise that just maybe their approach isn’t working


You make his position sound way more measured and responsible than it is.
His ‘effective safety measures’ are something like A) solve ethics B) hardcode the result into every AI, I.e. garbage philosophy meets garbage sci-fi.
This guy is going to be very upset when he realizes that there is no absolute morality.
A good chunk of philosophers do believe there are moral facts, but this is less useful for these purposes than one would think
yeah it’s been absolutely hilarious to watch this play out in LLM space. so many prompt configurations and model deployments with so very many string-based rule inputs, meant to be configuring inviolable behaviour, that still get egregiously broken
and afaict none of the dipshits have really seemed to internalise that just maybe their approach isn’t working